




İnsan beyni, GPT-4’e kıyasla çok daha verimli çalışarak saatte düşük bir güçle karmaşık işlemleri gerçekleştirebilir. En temel noktadan başlayalım. Bilgisayarlar, 1’ler ve 0’lardan oluşan ikili dilde çalışır; bu, esasen yüksek ve düşük elektrik akımlarını temsil eder. Bu ikili sistem, tüm dijital iletişimin temelidir. Bir dizi dönüştürme yoluyla bu ikili sayılar, harfler ve kelimeler dahil her şeyi temsil edebilir.
Geleneksel bilişimde, bir kelimenin temsili bağlamdan yoksundur. Örneğin, “toz almak” ve “üzerindeki toz” ifadelerinde “toz” kelimesi aynı şekilde temsil edilir, ancak anlamları farklıdır. Bağlamsal kelime embedding’leri burada devreye girer. Bu embedding’ler, kelimelere bağlamlarına göre farklı sayılar atar, bu da dilin daha ayrıntılı bir şekilde anlaşılmasını sağlar.
Embedding ve vektörler
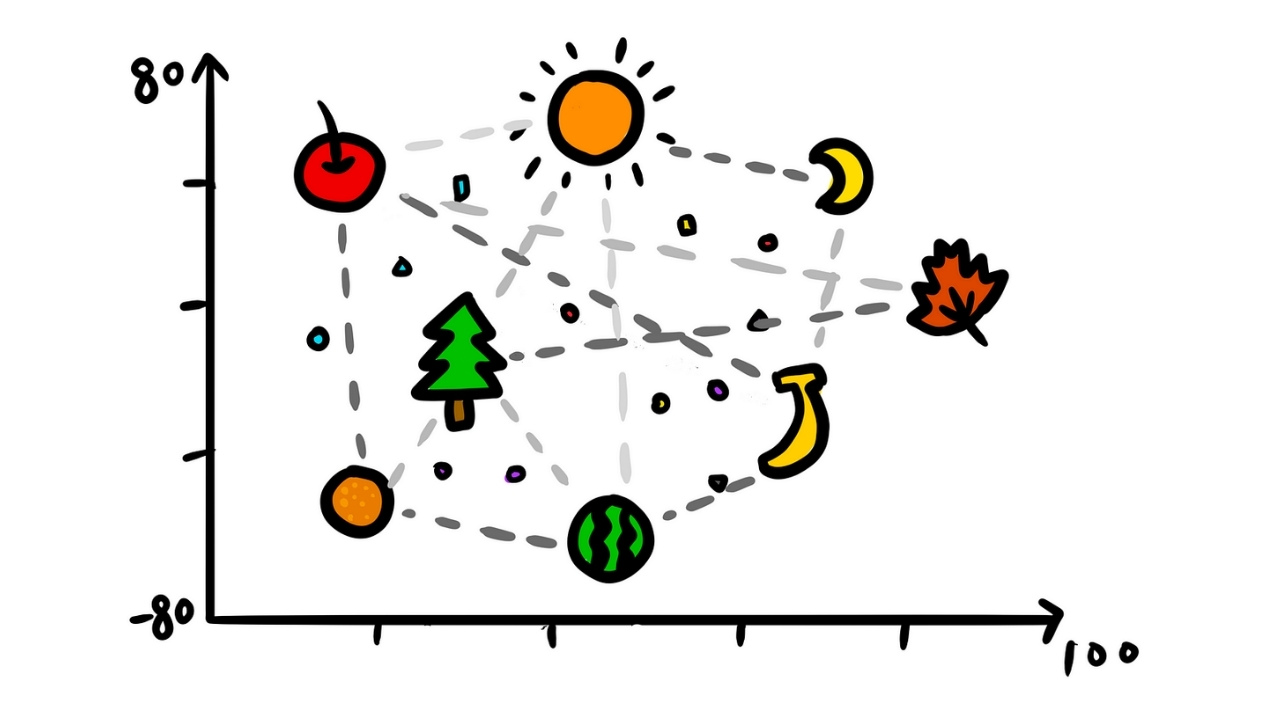

Embedding’ler, kelimelerin bağlam ve anlamını dikkate alan sayısal temsillerdir. Bu embedding’ler, birçok boyuta sahip vektör uzaylarında bulunur. Örneğin, OpenAI GPT-4 1536 boyutlu vektör uzaylarını kullanır. Her boyut, kelimenin anlamının farklı bir yönünü temsil eder.
Yüksek boyutlu vektör uzayları inanılmaz derecede geniş olabilir, bu da benzer vektörleri verimli bir şekilde işlemek ve aramak için zorluk çıkarır. Burada Hiyerarşik Gezinilebilir Küçük Dünya (HNSW) algoritması devreye girer. HNSW, büyük ağlarda bile çoğu düğümün birkaç adım içinde erişilebilir olduğu sosyal ağları taklit eder. Bu, yüksek boyutlu uzaylarda verimli arama ve işlemeyi mümkün kılar.
İnsan beyni ile ve GPT-4’ün karşılaştırılması

Beyinlerimiz inanılmaz derecede verimlidir, GPT-4 ile karşılaştırıldığında minimal güçle karmaşık işlemleri gerçekleştirir. GPT-4 büyük veri merkezleri ve önemli miktarda enerji gerektirirken, insan beyni saatte yaklaşık 24 watt güçle çalışır. GPT-4 ile insan beyninin verimlilik farkı, insan bilişinin harikasını ortaya koyar.
Vektör veri tabanları nasıl çalışır?
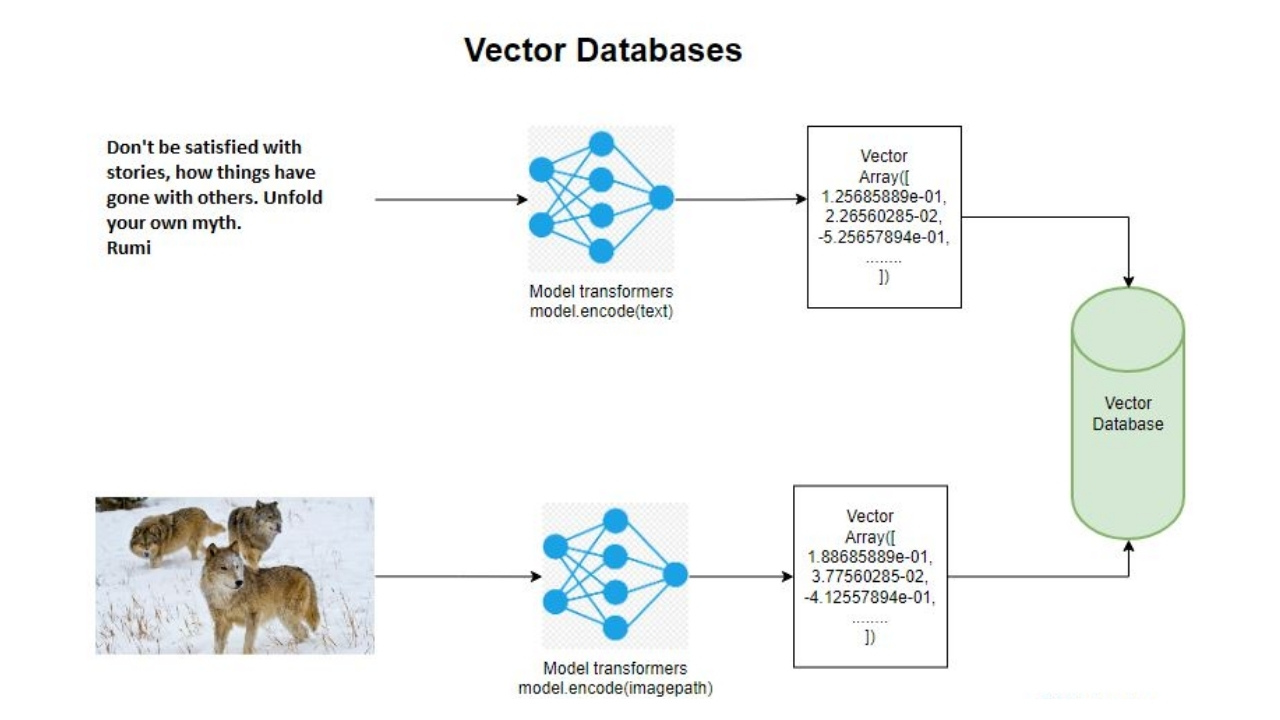
Vektör veri tabanları, yüksek boyutlu uzaylarda vektörleri (verilerin sayısal temsilleri) depolar ve arar. HNSW gibi algoritmaları kullanarak en yakın komşuları verimli bir şekilde bulurlar. Bu da hızlı ve doğru aramalar sağlar. Bu, öneri sistemleri, resim arama ve doğal dil işleme gibi uygulamalar için çok önemlidir.
Vektör veri tabanlarının karşılaştırılması:

- ChromaDB: Basit projeler için mükemmel bir başlangıç noktasıdır. Python ile kolayca entegre olur ve hızlı kurulum sağlar. Ancak, üretim düzeyinde uygulamalar için ölçeklenebilirlik ve performans açısından yetersiz kalabilir. Son güncellemeler, hızını ve bellek kullanımını iyileştirerek daha rekabetçi hale getirmiştir.
- Pinecone: Yönetilen bir vektör veri tabanı hizmeti sunar. Kullanım kolaylığı ve hızlı kurulum sağlar, ancak veri üzerinde şeffaflık ve kontrol eksikliği nedeniyle sıkı gizlilik ve uyumluluk gerektiren projeler için uygun değildir.
- FAISS: Tam teşekküllü bir veri tabanı değil, bir kütüphanedir, bu nedenle büyük ölçekli üretim kullanımı için daha az uygundur. Küçük ölçekli, deneysel projeler için idealdir.
- Milvus: Umut verici görünüyordu ancak hata ve belge eksiklikleri nedeniyle kullanımı zor oldu. Yerel olarak Docker’da çalıştırmak oldukça keyifliydi, ancak üretim ortamları için yeterince kullanıcı dostu ve güvenilir değildi.
- Pgvector: PostgreSQL için bir vektör uzantısıdır. Mevcut PostgreSQL kurulumlarıyla iyi entegre olur, ancak yüksek eşzamanlılıkta performans ve doğruluk sorunları yaşar. Küçük projeler için iyi bir seçenek olabilir, ancak yüksek performans gereksinimleri için uygun değildir.
- Redis: Vektör arama özelliği ile iyi performans ve kolay entegrasyon sunar. Ancak, vektörlerde uzmanlaşmamıştır ve uzun vadede çekirdek dışı özelliklere bağlılıkları belirsizdir.
- Qdrant: Açık kaynak modeli, mükemmel performansı ve güçlü topluluk desteği ile öne çıkar. Hem bulut hem de kendi kendine barındırılan seçenekler sunar, bu da onu çeşitli proje ihtiyaçları için esnek kılar. Popüler kütüphanelerle entegrasyonu ve kullanıcı desteğine odaklanması, onu vektör veri tabanları için en iyi seçenek haline getirir.
- Weaviate: Zengin özellik seti ve topluluk desteği ile dikkat çeker, ancak performans açısından Qdrant’a göre geride kalabilir. Yine de kapsamlı yetenekleri nedeniyle değerlendirilmeye değer sağlam bir alternatiftir.
Yüksek boyutlu veriler için en iyi vektör veri tabanı: Qdrant

Vektör veri tabanları, yüksek boyutlu verileri işlemek için güçlü araçlardır. Her veri tabanının güçlü ve zayıf yönleri vardır, ancak Qdrant, performans, ölçeklenebilirlik ve topluluk desteği açısından en iyi seçenek olarak öne çıkmıştır. Ancak, en iyi seçim proje ihtiyaçlarınıza bağlıdır, bu nedenle kapsamlı değerlendirme ve test yapmak önemlidir.
Kaynak: GPT-4, Olaf Górski